
import yfinance as yf
import pandas_datareader as pdr
import pandas as pd
from datetime import datetime
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
日本語フォント設定(必要に応じて変更)
plt.rcParams[‘font.family’] = ‘Meiryo’
現在の日付
today = datetime.today().strftime(‘%Y-%m-%d’)
株価データの取得
ticker = input(“銘柄コード(ティッカーシンボル)を入力してください: “)
print(f”\n=== {ticker}の株価データを取得中 ===”)
stock_data = yf.download(ticker, start=”2022-01-01″, end=today)
if stock_data.empty:
print(“データが見つかりませんでした。終了します。”)
exit()
マルチインデックスを解除
stock_data.columns = stock_data.columns.get_level_values(0)
経済指標データの取得
print(“\n=== 経済指標データを取得中 ===”)
economic_data = pdr.get_data_fred(“UNRATE”, start=”2022-01-01″, end=today)
economic_data.rename(columns={“UNRATE”: “UnemploymentRate”}, inplace=True)
経済データの補間
economic_data.index.name = “Date” # インデックス名を統一
economic_data = economic_data.reindex(stock_data.index, method=”ffill”)
データ統合
print(“\n=== データを統合中 ===”)
merged_data = pd.concat([stock_data, economic_data], axis=1)
merged_data[‘SMA_5’] = merged_data[‘Close’].rolling(window=5).mean() # 移動平均線
merged_data[‘SMA_20’] = merged_data[‘Close’].rolling(window=20).mean() # 長期移動平均線
merged_data[‘Target’] = (merged_data[‘Close’].shift(-1) > merged_data[‘Close’]).astype(int)
merged_data.dropna(inplace=True)
特徴量とターゲット変数
features = merged_data[[‘Close’, ‘High’, ‘Low’, ‘Open’, ‘UnemploymentRate’, ‘SMA_5’, ‘SMA_20’]]
target = merged_data[‘Target’]
データ分割
X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.2, random_state=42)
モデル構築
print(“\n=== モデルを構築中 ===”)
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
予測と精度
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
print(f”\n=== 予測結果 ===\nモデルの精度: {accuracy:.2f}”)
翌日の予測
latest_features = features.iloc[[-1]] # 特徴量名を保持
prediction = model.predict(latest_features)
prediction_proba = model.predict_proba(latest_features)
print(f”翌日の株価予測: {‘上昇’ if prediction[0] == 1 else ‘下落’} (確率: {prediction_proba[0][1]:.2f})”)
グラフ表示
plt.figure(figsize=(10, 6))
plt.plot(merged_data.index, merged_data[‘Close’], label=”終値”, color=”blue”)
plt.title(f”{ticker} 株価推移と予測結果”)
plt.xlabel(“日付”)
plt.ylabel(“株価”)
plt.legend()
plt.grid()
plt.show()
データ保存
merged_data.to_csv(f”{ticker}_merged_data.csv”, encoding=”utf-8-sig”)
print(f”\n統合データを {ticker}_merged_data.csv に保存しました。”)
C:\Users\user\Desktop\python>4.py
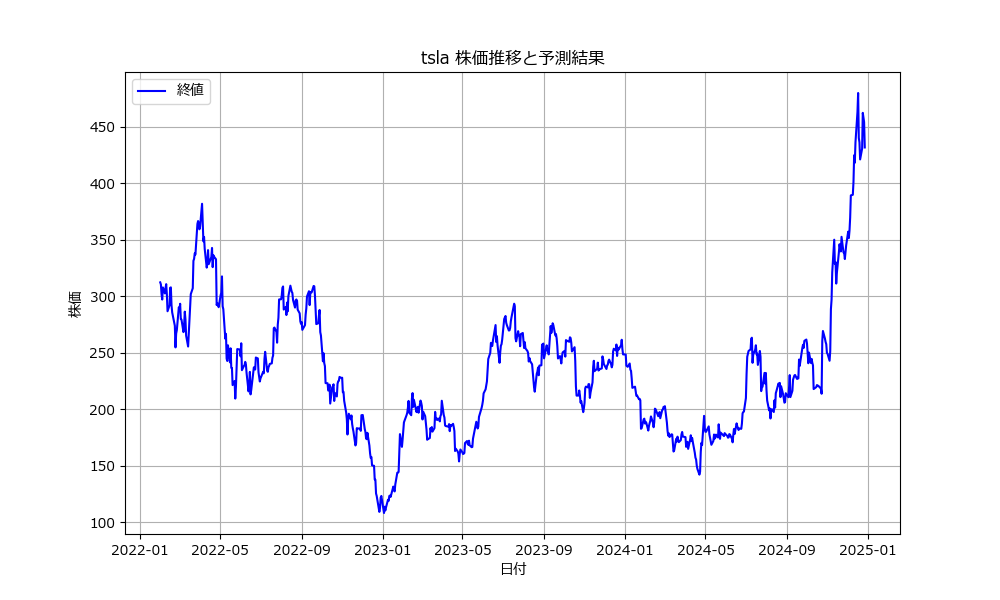
銘柄コード(ティッカーシンボル)を入力してください: tsla
=== tslaの株価データを取得中 ===
[100%**] 1 of 1 completed
=== 経済指標データを取得中 ===
=== データを統合中 ===
=== モデルを構築中 ===
=== 予測結果 ===
モデルの精度: 0.48
翌日の株価予測: 下落 (確率: 0.02)
統合データを tsla_merged_data.csv に保存しました。
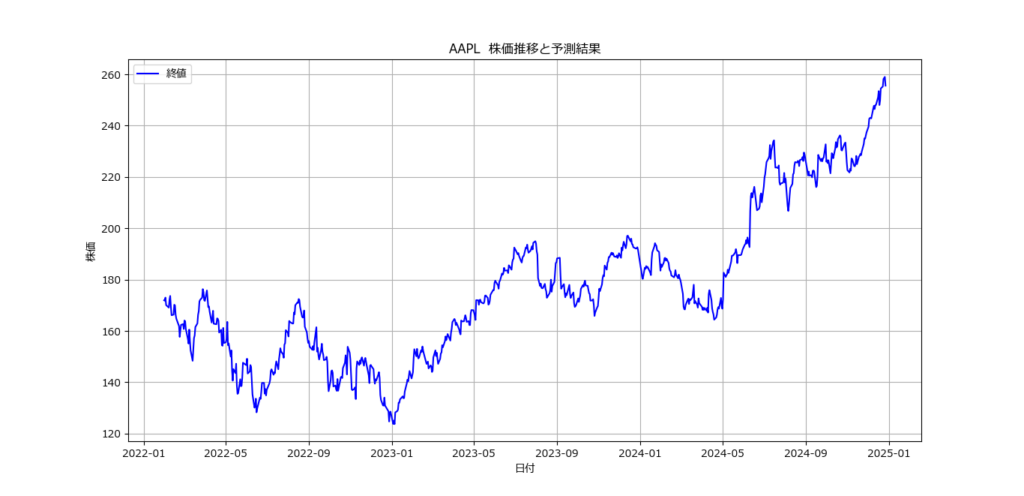
銘柄コード(ティッカーシンボル)を入力してください: AAPL
=== AAPL の株価データを取得中 ===
[100%**] 1 of 1 completed
=== 経済指標データを取得中 ===
=== データを統合中 ===
=== モデルを構築中 ===
=== 予測結果 ===
モデルの精度: 0.56
翌日の株価予測: 下落 (確率: 0.30)
統合データを AAPL _merged_data.csv に保存しました。
C:\Users\user\Desktop\python>4.py
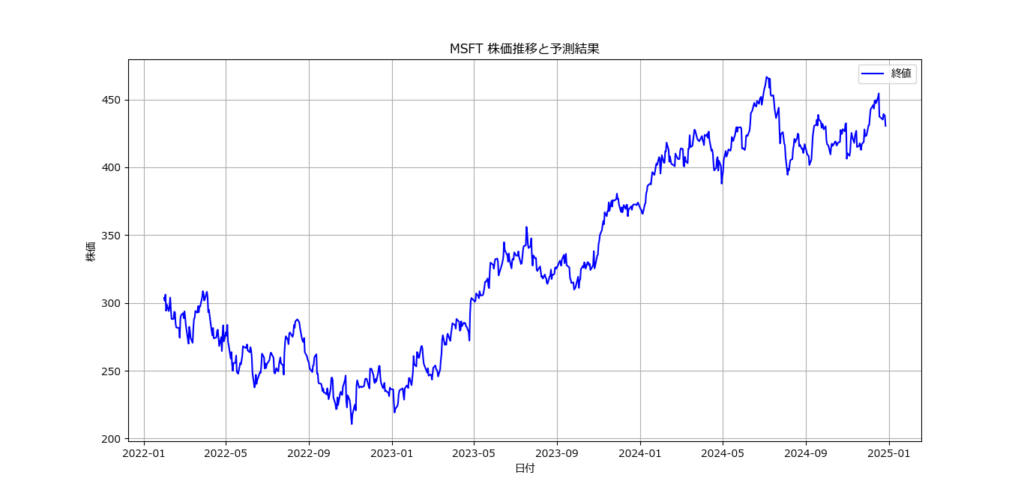
銘柄コード(ティッカーシンボル)を入力してください: MSFT
=== MSFTの株価データを取得中 ===
[100%**] 1 of 1 completed
=== 経済指標データを取得中 ===
=== データを統合中 ===
=== モデルを構築中 ===
=== 予測結果 ===
モデルの精度: 0.59
翌日の株価予測: 下落 (確率: 0.03)
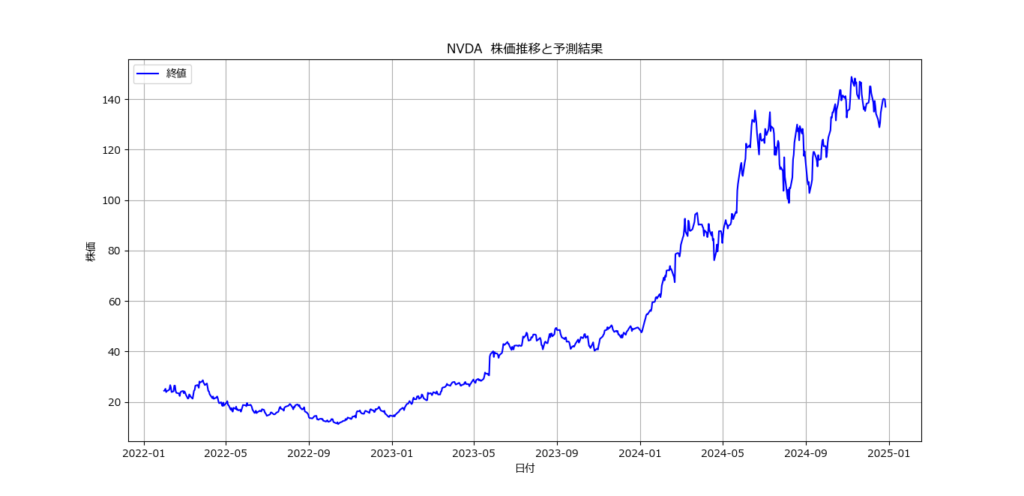
銘柄コード(ティッカーシンボル)を入力してください: NVDA
=== NVDA の株価データを取得中 ===
[100%**] 1 of 1 completed
=== 経済指標データを取得中 ===
=== データを統合中 ===
=== モデルを構築中 ===
=== 予測結果 ===
モデルの精度: 0.52
翌日の株価予測: 下落 (確率: 0.20)
今下落傾向にあるが、今後上昇が期待できる銘柄
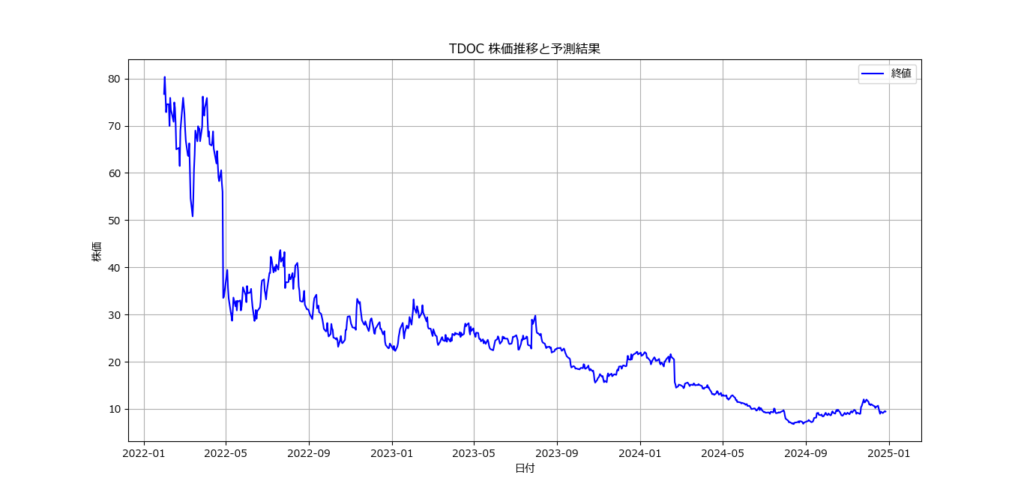
銘柄コード(ティッカーシンボル)を入力してください: TDOC
=== TDOCの株価データを取得中 ===
[100%**] 1 of 1 completed
=== 経済指標データを取得中 ===
=== データを統合中 ===
=== モデルを構築中 ===
=== 予測結果 ===
モデルの精度: 0.51
翌日の株価予測: 下落 (確率: 0.19)
統合データを TDOC_merged_data.csv に保存しました。
C:\Users\user\Desktop\python>4.py
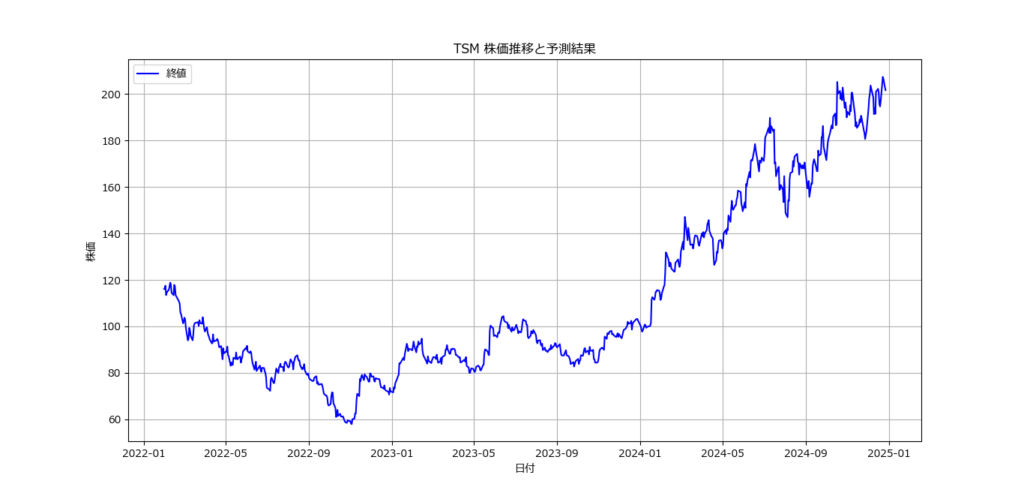
銘柄コード(ティッカーシンボル)を入力してください: TSM
=== TSMの株価データを取得中 ===
[100%**] 1 of 1 completed
=== 経済指標データを取得中 ===
=== データを統合中 ===
=== モデルを構築中 ===
=== 予測結果 ===
モデルの精度: 0.44
翌日の株価予測: 下落 (確率: 0.02)
【プログラムの解説】
このプログラムは、指定された株式のティッカーシンボル(銘柄コード)を基に株価データを取得し、経済指標データと統合して予測モデルを構築し、翌日の株価が上昇するか下落するかを予測するものです。
プログラムの概要
- 必要なライブラリのインポート
- 株価データを取得するために
yfinanceを使用。 - 経済指標データ(米国失業率)を取得するために
pandas_datareaderを使用。 - データ処理に
pandas、グラフ描画にmatplotlib。 - 予測モデルを構築するために
sklearnのRandomForestClassifierを使用。
- 株価データを取得するために
処理の流れ
1. ユーザー入力
- ティッカーシンボルをユーザーから入力(例: TSLA)。
- 株価データを
yfinanceから取得。 - データが見つからない場合はプログラムを終了。
2. データの取得と統合
- 株価データと経済指標データ(失業率)を取得。
- 両方のデータを日付で統合し、新しい特徴量を作成:
- 短期移動平均線(SMA_5)
- 長期移動平均線(SMA_20)
3. 目標変数の作成
- 翌日の株価が当日の株価より上がる場合に1、それ以外は0をターゲット変数(
Target)として設定。
4. データの分割
- 特徴量(株価や経済指標)とターゲット変数(株価の上下)を分ける。
- トレーニングデータとテストデータに分割(8:2の割合)。
5. モデル構築
- ランダムフォレスト分類器(
RandomForestClassifier)を使用して学習。 - テストデータで予測を行い、精度を表示。
6. 翌日の株価予測
- 最新データを使用して翌日の株価が「上昇」か「下落」かを予測。
- 予測確率も表示。
7. グラフの表示
- 株価の推移を可視化。
- 終値を日付と共にプロットし、予測結果を補足。
8. データの保存
- 統合データ(株価・経済指標・移動平均線など)をCSVファイルとして保存。
機能のポイント
- 特徴量の生成
- 短期(5日)と長期(20日)の移動平均線を使うことで、トレンドを捉える。
- 機械学習モデル
- ランダムフォレスト分類器は、特徴量間の非線形関係を扱うのに適している。
- 翌日予測
- 株価の上昇/下落を確率付きで予測する。
- 可視化
- 終値の推移をグラフで表示することで、データを直感的に理解可能。
想定される利用例
- 指定した銘柄(例: TSLA、AAPL)の株価を分析し、翌日の動きを予測。
- 投資判断の補助として活用。
このプログラムを日本株で利用する場合、ティッカーシンボル(例: 6501.Tなど)を適切に指定する必要があります。また、経済指標データも日本市場向けに変更することでより適した予測が可能です。

コメント